


Unit1 表达式解析
喜报喜报!OO正课它来了!
还在因为找不到对象发愁吗?还在因为刚充值Gemini找不到用武之地而彷徨吗?
这些都不是问题,因为OO足够劲爆!
那还等什么,就让我们拆开OO为我们送上的第一份大礼——
表达式解析
第一次作业
啊?表达式解析
1、表达式解析的定义
在这里,我直接引入课程组对问题的描述。
读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 3 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
在本次作业中,展开所有括号的定义是:对原输入表达式 E 做恒等变形,得到新表达式 E′,且 E′ 中不含有字符(、)和空白字符
(有关单变量表达式的详细内容请见文末)
什么意思呢?拆括号+合并同类项,没了。
2、难点重重
一看到题目,大脑就麻木了。最多嵌套三层的括号,还加入了令人头疼的乘方运算。此外,我们敬爱的课程组还引入了神秘的未知数x。高端如Java,也没有处理未知数乘法的现成函数。更离谱的是,他们仨还能打出组合技。让我们来直观感受一下这些东西有多头疼:
- (+- x*x*3*x^+002 +12)^2*x
是的,我们还需要面对莫名其妙的先导零、莫名其妙的空白符以及莫名其妙的+-组合。
还有一件事,题目可没说常量有多大啊。
- (+- x*x*3*x^+002+121321198935894123487835410827587203471287180)^2*x
这个也是合法的。
噫,我找到对象了
好吧,问题的第一步在于,我们要怎么解析个又臭又长的字符串,我们要怎么根据文法规则把它划分为Expr、Term、Factor这几部分。
就在我们一筹莫展的时候,我们敬爱的课程组送来了一份代码。Unit1_training?别搞啊,我这份作业还没写完呢,怎么还有新的。你千万不能这么想!因为这是本次作业有且仅有的提示(如果你不关注公众号的话)。文件夹中有两份代码,basic和advance。于此,我们的表达式解析之旅正式开始了。
1、basic-正则表达式
不难发现,表达式被 + / - 划分,分为多个项。项由 * 划分,分为多个。项就更好说了,题目都给出了他们的形式化表达,直接转化为正则表达式就行了。(例:常量因子 [+-]?\d+)我们只需要配合Java中的Matcher 和 Pattern类就可以很轻松的划分出各个部分。
主函数内部
private static final String patternTerm = "\\d+(\\*\\d+)*"; //正则表达式,用来提取项 |
Expr类内部
public Term(String s) { |
至于计算部分,课程组也给了我们提示,利用函数递归先进后出的特点,我们可以先处理+/-,然后是*
if (position != -1) { |
嗯?这不就是数据结构学的表达式树的计算方法吗?原来是老朋友,看来这次作业也没多难,……吗?不!千万不要忘了,我们还有乘方运算,我们还有嵌套的三层括号!你不妨想想,这样的情况下,处理函数会有多么复杂。
等等,为什么要在Java中用“函数”这个术语,不应该是“方法”吗?恭喜你,你发现了华点。我们接着往后想,假设要把上面这一坨代码转化为C语言代码,有哪里需要改动呢?把expr改成以term为元素的数组!把term改为以factor为元素的数组!改scanner为scanf…怎么越想越不对劲啊,这和C语言没区别啊!
对了,这是因为我们借着面向对象的幌子,写了一份很过程的代码。无异于找到npy但是牵不了手(悲
以下内容由
Gemini提供:
既然聊到了过程化,不如我们再往深挖一步,直接从计算机科学的底层理论上给正则表达式判个死刑。
在编译原理的乔姆斯基文法体系中,正则表达式属于3型文法(正则文法)。它在底层的数学模型叫做有限状态自动机(FSA)。这台机器有个致命的弱点:它没有记忆。(寄存器里面那个叫状态)
遇到简单的连续加减乘除,状态机还能凑合跑。但一旦遇到我们题目中万恶的嵌套括号,比如(((x+1)^2)),状态机就彻底懵了。它遇到第一个(切换状态,遇到第二个(还在那个状态,等遇到)的时候,它根本不知道前面到底配对了几个左括号,因为它内部压根就没有“计数器”或“栈”这种物理结构。
要想完美解析嵌套括号,在数学理论上我们必须跨越维度,使用带有栈结构的下推自动机(PDA),这属于更高级的2型文法(上下文无关文法)。想要利用栈,我们就要调用函数递归,学过程序设计的同学都体验过递归的痛苦,这无疑加大了代码难度。
所以,用纯正则去解多项式嵌套,不仅是工程上的“代码坟墓”,更是数学理论上的“逆天而行”。
PS:并不是说不能用正则表达式做这道题,因为按照往年经验,第一次作业用正则表达式是主流,更何况这个世界上有正则仙人。
那么,真正的 OO 玩家到底应该怎么做?不要着急,让我们点开advance,步入 AST的奇妙世界。
2、advance-递归下降
什么是递归下降?让我们翻出一张陈年老图。
这和我们的递归下降有什么关系,不要急,再看下面这张图。其中Parser是我们引入的新类,它负责将整个表达式进行划分。
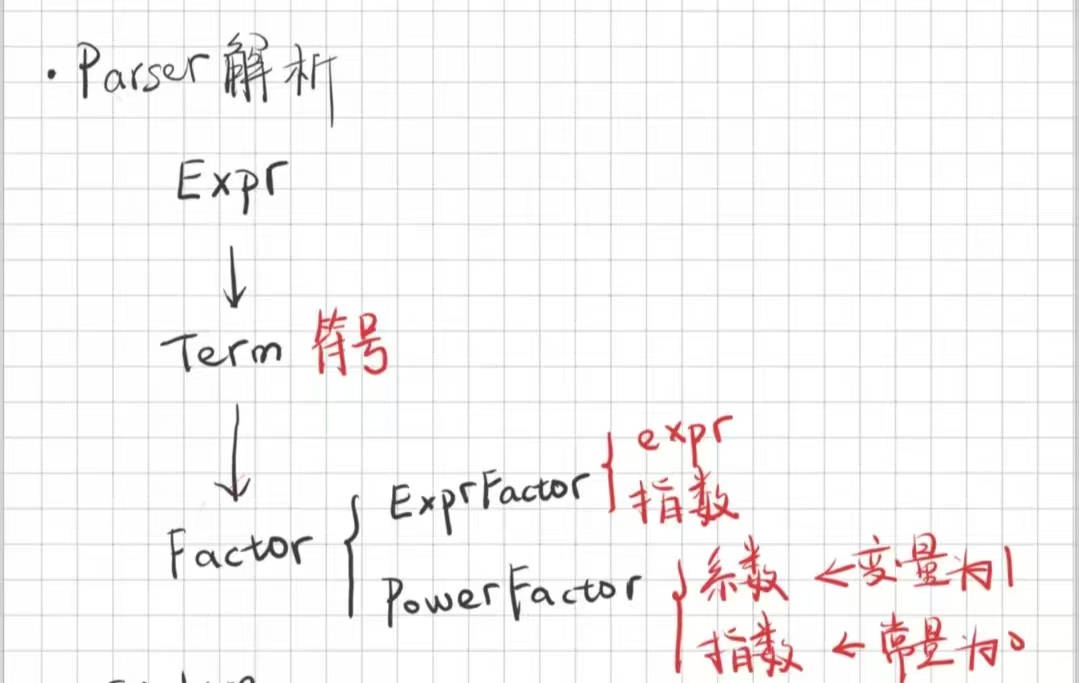
Parser 的运作和周王朝的运作有什么相似之处?这就不得不提到本题最重要的三种类了Expr、Term、Factor。
- 我是
Expr(天子):我高居庙堂,俯瞰整个帝国。在我眼里,天下无非就是被+或-这两条大河划开的几个大行省——也就是一堆Term(项)。天子是不干粗活的,我不做任何具体的数学运算。我只负责宣旨,new一个ArrayList<Term>,然后把切出来的行省一个个装进去。 - 我是
Term(诸侯/士大夫):我是天子任命的行省总督。在我眼里,我的辖区无非是被*划开的几个县城——也就是一堆Factor(因子)。我也很懒,我只负责拿个ArrayList<Factor>把县城存起来。对了,作为一方诸侯,我还握有辖区的兵权(记录前面的正负号boolean negation),毕竟到了最后清算的时候,整个行省是正还是负,得我这个“项”来兜底。 - 我是
PowerFactor(平民):我是实干家。我可以是一个怀揣 c 两白银,但名下没有半亩土地(x^0)的商贾(常数c)。我也可以是一个兜里只有 1 两散银,但坐拥 n亩良田的自耕农(x^n)。但是你看,不管是带符号的常数c,还是带指数的 x,我们的本质都是一样的(c * x^n)。 - 我是
ExprFactor(平民):我是一个白日幻想家。我可没有什么白银、什么土地。我负责管理我的王国,我的王国里也有天子、也有士大夫和平民。怎么来的?这你别管!你只要明白,这个王国的价值,就是我的价值。如果我想的话,我还能给它搞个平方(^+n)。
Expr、Term、Factor,他们负责各自任务,对下属绝对信任。至于Expr、Term、Factor三者的域,可以自行思考(上文其实有提示)。
至于Parser这个负责解析文法的上帝,创造了Expr、Term、Factor的实例化对象,并将他们衔接起来,parseExpr负责拆分出表达式中的各个项term,并将他们存入Terms这个容器中。parseTerm负责拆分出因子中的各个因子factor,并将他们存入Factors这个容器中。parseFactor则负责区分两种factor,并为他们分配相应的对象空间。
终于,我们找到了真正的对象(还是三个,有点花心)。接下来,任务就变得轻松了。
哎,都是为了这个家
1、统一度量衡(预处理)
不知你是否还记得,我们有一些朋友不太安分:
莫名其妙的先导零、莫名其妙的空白符以及莫名其妙的+-组合
想要处理他们,其实一点也不难。不难发现,空白符除了让字符串变得格外丑陋,基本没有任何作用,所以我们只需要无脑去掉所有空白符就可以了。
//Step1:去除一切空白符 |
那么那些连续的+-号呢?题目说表达式前面可能有一个,项前面可能一个,常数因子前面也可能有一个,最多可能有三个连续的+/-。但实际上,有几个都无所谓,因为只要是连续的+/-,我们都可以把它化简为一个。
//Step2: 去除连续的"+"和"—" |
至于前导零和那个无限制的巨大的常量,其实就更简单了,因为Java提供了极其丰富的库。BigInteger类无疑是解决这个问题的不二之选,它自带的初始化方法能把字符串中前导零全部忽略。Integer.parseInt(String input)方法同样也可以解决前导零的问题,只不过它适用于Integer类(int的包装器类型)。
2、税收系统(Poly类与evaluate方法)
周王朝的运作当然离不开money,既然我们已经成功构建了基本的国家体系,那么是时候实现税收系统了。
问题来了,既然加入了未知数x,那么我们就不能用简单的int或者BigInteger来表示最终计算的数值。这个时候,就要引入Poly类了。之所以这么做,是因为本次作业所有的值都可以归纳为一个多项式。为了实现像int那样的计算,我们需要为Poly类补充相应的功能(加、减、乘、平方)。
那么要怎么把Expr、Term、Factor转化为多项式呢?只需要为每个类设置一个evaluate方法就行了。需要注意的是,这里的evaluate方法调用是递归的,比如Expr的evaluate负责调用Term的evaluate方法,Term的evaluate负责调用Factor的evaluate方法。
3、启禀皇上
到了最后,我们通过调用Expr的evaluate方法,计算出来最终的Poly结果。万事俱备,我们只需要把最终的Poly打印出来,也就是覆写Poly的toString方法就可以了(之所以是覆写,是因为那个祖宗——Object类——自带此方法)。
皇上的时间很宝贵,我们的最终输出也是越短越好(性能分对此有要求)。我相信以大家的智商,都能想到如何输出最短的结果吧。不过,我还是在此稍微提醒一下,-2+x 比 x-2要多一个字符。
看到这里,你肯定已经胸有成竹了。加油,去谱写你的王国史诗吧!
第二次作业
在第一次作业基础上,本次迭代作业增加了以下几点:
- 本次作业支持嵌套多层括号。
- 新增指数函数因子
exp,其参数可以是任意因子。 - 新增选择式因子,一种形如
[(A==B)?C:D]的三目运算结构,要求程序具备判定因子A与B数学恒等性的能力。 - 新增自定义函数,支持
f(x) = 表达式形式的函数定义与调用。
因为新因子的添加过程和第一次作业基本一致,这里只讨论几个比较重要的问题。如何提升程序的速度是我们讨论的重点,尽管性能分与程序速度没有直接关系,但是TLE会公平地惩罚每一个忽视它的人。
哥们,你到底变不变啊?
本次作业还是需要我们沿用AST的思路,如果你在第一次作业使用的是正则表达式的写法,那么还是好好重构吧。如果你早就踏上了AST这条宏伟大道,那恭喜你,这次作业你应该很快就能做出来了。有多快呢?大概七个小时吧(本彩笔真的用了这么久,中饭都没吃)。我知道你想笑,但是你先别笑,因为后续的优化又消耗了我整整一天半,导致我压根没时间复习OS的Lab0实验,在extra中砍下了20分的高分。
那么问题来了,到底是什么东西折磨了我这么久?哈哈,等会你就知道了。
为了存储结果,我们不能再使用c*x^n这个模式了,要为它加上一个exp项c * x^n* exp(poly)。所以我们需要为这个新的形式准备一个新的数据结构。主流的数据结构有两种,一个是哈希表,另一个也是哈希表。我没有开玩笑,因为这两个哈希表有着本质上的不同——键值对的对象类型不同。前者的键是Node对象,里面存放着x的幂值int和exp的幂值poly,我们将它暂且称为NodeHash表,它的值则是系数coef;后者则简单很多,键是x的幂值int,值是一个链表,链表的元素是exp的幂值poly和系数coef组成的类Unit,我们暂且称这个哈希表为UnitHash 表。
正常人会选择前者,因为这样会减少对链表的遍历,速度快很多。事情真的是这样吗?你怎么知道Java是如何对待你的hashmap的?把键设置为一个新的类真的靠谱吗?我询问了Gemini,得到了一个惊人的答案——如果我们的Node类是可变对象,我们每次修改的时候都要将原先的Node去除,再插入新的Node,并且重新递归地计算hash值,这样速度反而更慢。仔细思考一下,我们的Node对象里面存放着Poly类,Poly类在初始化之后还要加、乘、乘方、取反,比npy(我还没有,悲)还善变!于是我恍然大悟,UnitHash表才是正解!NodeHash是死路一条!
我悟了,然后耗时7小时写出了第一份代码,自信满满地跟同学对拍——结果却惨不忍睹,我的代码基本上全是TLE!于是我决定剖析同学的处理方式(我借用了同学的源代码,当然这是违规的),发现他们竟然采用了那个被我排除的方法NodeHash,这不科学。
心灰意冷之下,我再次询问了Gemini,它这次给出了一个崭新的概念——事实不可变。我们不妨回忆一下Poly类的那些方法,除了ptermAdd之外,无论加、乘、乘方还是取反,无一不是在开头new了一个新的对象result,在方法的最后return了这个result。也就是说,这些方法并没有改变原先那个poly,而是制造一个新的对象,它们本质上是另一种初始化方式罢了,而ptermAdd,仅仅是这些初始化方法的辅助方法。在初始化之后,我们将不再有资格修改这个poly对象,这不就是不可变对象吗?为了彻底在代码层面保证这种不可变性,我将 Node 类中的所有属性都加上了 final 关键字,并且在构造器中一次性算好 hash 值并锁死在一个 final int 中。这样 HashMap 在发生碰撞寻址时直接返回常数,连重新计算哈希的开销都省了!所以,在这里,使用NodeHash表压根没有想象中那么危险。除此之外,我们还可以删除原来的深拷贝方法,进一步提升程序的效率。
这样,我被折磨的原因很清楚了——这些看起来可变的“事实不可变”对象把我骗得团团转。
哥们,你到底快不快啊?
当我更换完数据结构之后,速度虽然有所上升,但是还是比不过我的同学,对于上进(卷!)的我来说这肯定难以接受。我把同学的代码喂给AI,询问了原因。可是这次AI不买账了,它指出我的同学只是运气好,在面对有快速幂的我来说,比他们快才是正常现象。这下给我整不会了,明明是随机生成的测试点,我的同学怎么可能次次都运气好。鬼使神差之下,我删除了快速幂,然后奇迹发生了,我的代码快了10倍(5分钟到30秒)!显然,我被快速幂骗得团团转。
为什么会这样?让我们从这两个方面来剖析一下:
1、隐藏代价
在算数字的快速幂(比如 2^8)时,无论是算 2* 2还是16 *16,CPU执行一次乘法指令的时间都是O(1)。此时,减少乘法次数(快速幂)就是唯一的王道。但在多项式中,执行一次 A* B 的时间复杂度是 A的项数 * B 的项数。
随着指数的增大,快速幂会让两个体积巨大的中间结果互乘,导致单次乘法的开销呈平方级爆炸。这就好比普通连乘是拿一个庞大的结果去乘以最初那个微小且纯粹的底数(大象踩蚂蚁);而多项式快速幂则是强制让两个极度膨胀的中间结果互相相乘(巨兽互殴),这注定会引发性能上的灾难。
2、哈希爆炸
上述讨论的仅仅是单次乘法的开销,快速幂可以用更少的乘法次数弥补这一点。真正的问题在于快速幂产生的庞大的中间量上面。
多项式乘法不仅是循环相乘,还包含了极其耗时的合并同类项过程。快速幂在计算的过程中会产生很多中间量,合并化简的步骤将会多次进行哈希查找的工作,这其中的哈希冲突不计其数,一旦发生冲突,Java就会递归地调用equals操作,极大地增加了程序的复杂度。
由此可见,快速幂并不适用于多项式运算,我们在使用算法的时候要多加思考,而不是把它当作盲盒随意地使用。
哥们,你到底算不算啊?
几天后的周五,面对被hack的千疮百孔的程序,XJX回忆起提交中测的那个夜晚,当时的他是多么自信,认为自己选择了一条最正确的路……现在,XJX修复了自己的程序,而行刑者正等待下一个莽撞的少年。那么行刑者究竟是如何突破重重关卡,一路杀到我们面前的呢?没错,他们跟课程组签订了秘密的协议(误闯天家):
1 |
乍一看,这个样例的复杂度肯定过不了cost检测,但是课程组为我们准备了一个天坑:
Cost([(A==B)?C:D]) = Cost(A) + Cost(B) + choose(Cost(C), Cost(D)) + 5 |
没错,后面那一坨自定义函数的嵌套根本不会被算入cost,假设你的代码无脑计算了这一坨数据,那么无情的大刀就会落下,骇死我了。为了避免这恐怖的结局,我们必须在对选择因子evaluate的时候留个心眼——先判断真假,再决定选择哪一个因子去evaluate。
其实,不只是选择因子的evaluate需要多加注意,我们在选择解析自定义函数的方式时更要留神。如果你选择了暴力宏展开,也就是把f(x)定义中的x(形参)全部替换为realArg(实参),你可能也会出现这样的问题——一些无关的因子被暴力展开了,消耗了过多的时间。除此之外,考虑到String是不可变对象,对于层层嵌套,每一次展开都会产生很多的String对象,这会使得GC回收器压力暴增,消耗过多的算力。
正确的做法是先把f(x)解析成expr的形式,就像后面需要化简的表达式一样,一旦f(x)被调用,就把它evaluate成Poly,然后使用Poly内置的替换方法把x全部替换为realArg。
public Poly polySubstitute(Poly argPoly) { |
实际上,我们还可以为每个AST成员创立一个funcEvaluate方法,对于除了powerFactor之外的成员,它的功能和普通evaluate完全一致;但是在遇到powerFactor的时候,它不会返回x^n,而是返回argPoly^n。这两种函数解析的方法各有优劣,我们在第三次作业再展开讨论。
现在,本次作业最凶险的关卡已经暴露无疑了,加油,继续书写你的史诗吧。
第三次作业
因为不可抗因素(懒),第三次作业的分享延后了一个多月,内容并不全面,还请见谅。
进化吧,我的函数
在第三次作业中,我们的普通函数摇身一变,变成了递归函数。然而这并没有什么影响,我们依旧可以根据前面使用过的方法来实现这个递归函数。为了避免TLE,大多数同学会选择使用记忆化的方法来处理递归函数,为可能出现的递归函数设置一个存储池。存储池中的内容就因人而异了,如果你选择的是将x替换为argPoly这一方法,那么你完全可以存储一个展开后的Poly值;如果你选择的是funcEvaluate那种方法,你存储的就是一个仍需evaluate的表达式树。这两种方法都可以通过测试,但是前者速度更快,后者可扩展性更好。为什么前者速度更快呢?大家可以从“大数乘方”的角度考虑,和“快速幂不快”(详见“哥们,你到底快不快啊?”)在本质上是一个问题。后者可扩展性更好是因为它保留了表达式的结构,试想一下,如果未来函数中可以引入求导算子,把f(x)计算成多项式再替换x的方法还行得通吗?显然不行:
定义 f(x) = dx((x + x^2)) |
在我们这一届,助教为了避免歧义限制了自定义函数内的算子,但是这不代表在未来的课程中,又或者是未来的工作中,你不会面临这个问题。(如果我当上了助教,我会极力劝说课程组修改的,哈哈哈哈哈哈哈哈哈)除此之外,我认为还有一个很失败的设计:
除此之外,为了限制不合理的hack,我们要求输入表达式的代价
Cost(Expr) <= 5000,同时要求自定义递推函数的代价Cost(Func)<=2000。注意,对于递推函数f{n},需要保证对于任意 0≤i≤5,cost(f{i})<=2000。
题目中f{n}的cost限制对于0≤i≤5全部成立,丝毫没有考虑到表达式中或许根本不存在f{5}的调用,计算f{5}完全是多余的步骤,既然选择表达式中未被选择的那个因子不算在cost里面,凭什么f{5}要被限制呢?如果日后设计程序的时候,用户的最大需求是f{100},我们也要在每次计算表达式之前把100个递归函数都计算一遍吗?所以,真正可靠的做法是“惰性求值”,也就是在f{5}真正被调用的那一刻才去计算这个递归函数,然后把它储存在记忆池子里。样例如下:
public static Poly getRfDpPoly(Integer funcId) { |
进化吧,我的GCD
为了追求性能分,很多同学会选择提取exp因子中的公因式,然后通过比较选择出最短的形式。而这,成为了第三次作业中被hack最多的点。如果你不知道hack的方法是什么,请测试下面这个数据点:
1 |
这个数据点生效的原因是,每一次^2都会产生两种不同的情况,为了比较长短,你的代码会生成两种情况对应的字符串,在生成字符串的过程中,你又会遇见新的^2,代码又会生成两种字符串比较长短。就这样,大量的^2叠加引发了指数爆炸,造成CPU超时。
解决的办法很简单,我们把每一个已经计算过的字符串记忆下来就行了,也就是为每一个Poly维护一个String strCache变量。
本单元的分享就到此为止了,感谢您的阅读。

